Day 93: Building a Production-Grade Log Search Engine
What We’re Building Today
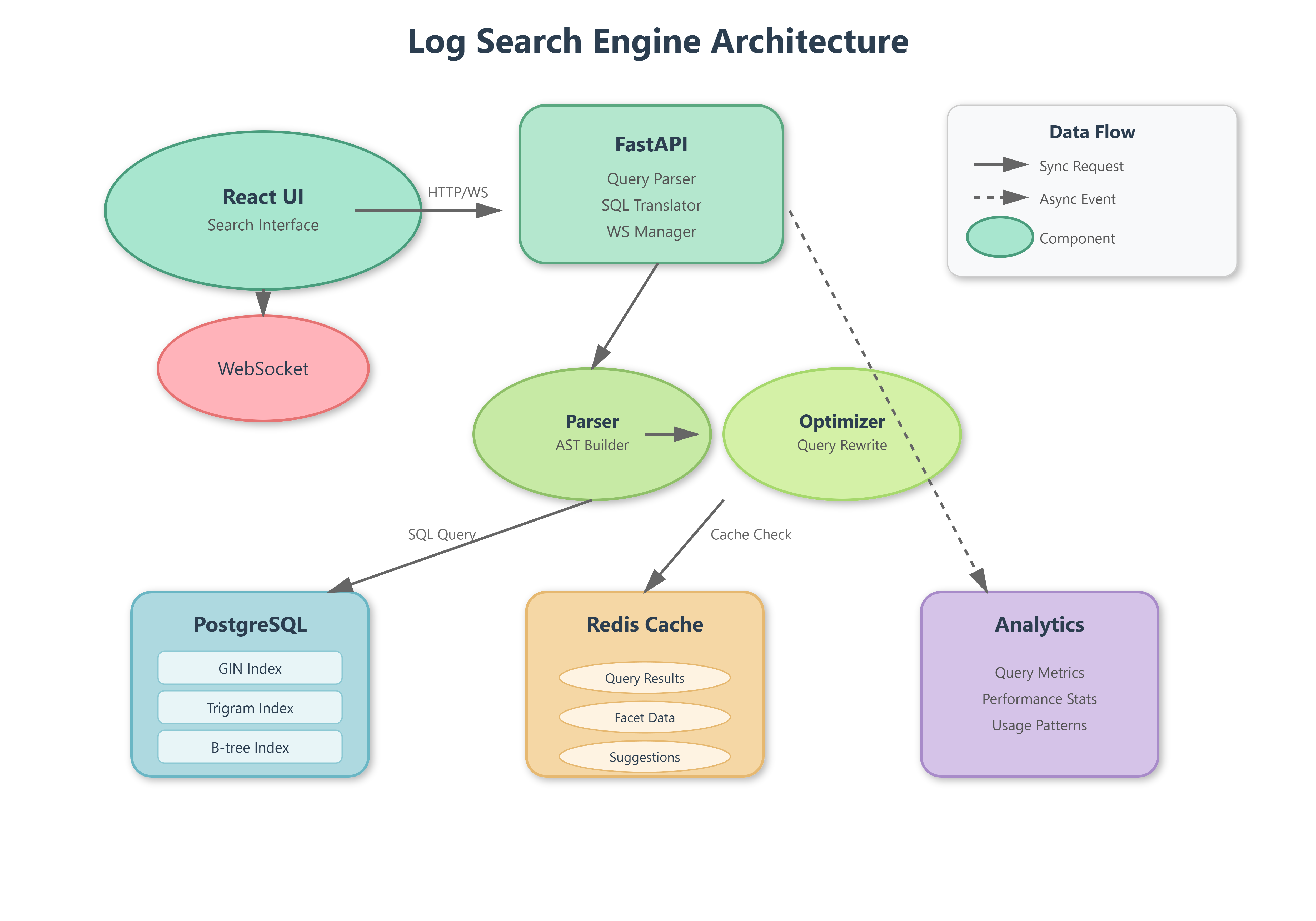
Today we’re building a high-performance log search engine that processes thousands of queries per second across millions of log entries. We’ll implement a custom query language, intelligent indexing strategies, real-time search capabilities, and optimization techniques used by companies like Datadog and Splunk.
Key Components:
Advanced search interface with query builder
Custom query language parser (field:value, wildcards, boolean operators)
Multi-strategy indexing (inverted index, trigram matching, GIN indexes)
Real-time search with WebSocket updates
Performance optimization with caching and query planning
The Search Challenge at Scale
When Datadog processes 1 trillion log events daily, searching through them requires sophisticated engineering. Traditional database LIKE queries collapse at scale. A single unoptimized search across 10 million logs can take 30+ seconds and lock your database. Production search engines need sub-second response times while handling concurrent queries.
The solution combines multiple indexing strategies, intelligent query parsing, and aggressive caching. Elasticsearch dominates this space, but understanding the underlying mechanisms—inverted indexes, tokenization, scoring algorithms—makes you a better infrastructure engineer regardless of which tool you use.
System Context: Week 11 Integration