Day 59: Data Visualization API
Transform Raw Metrics into Actionable Intelligence
Welcome back! Today we’re building something incredibly powerful - the analytics engine that transforms billions of raw notification events into the beautiful charts and insights you see in production dashboards. This is the system that powers everything from Netflix’s delivery metrics to Slack’s performance analytics.
What We’re Building Today
By the end of this lesson, you’ll have created:
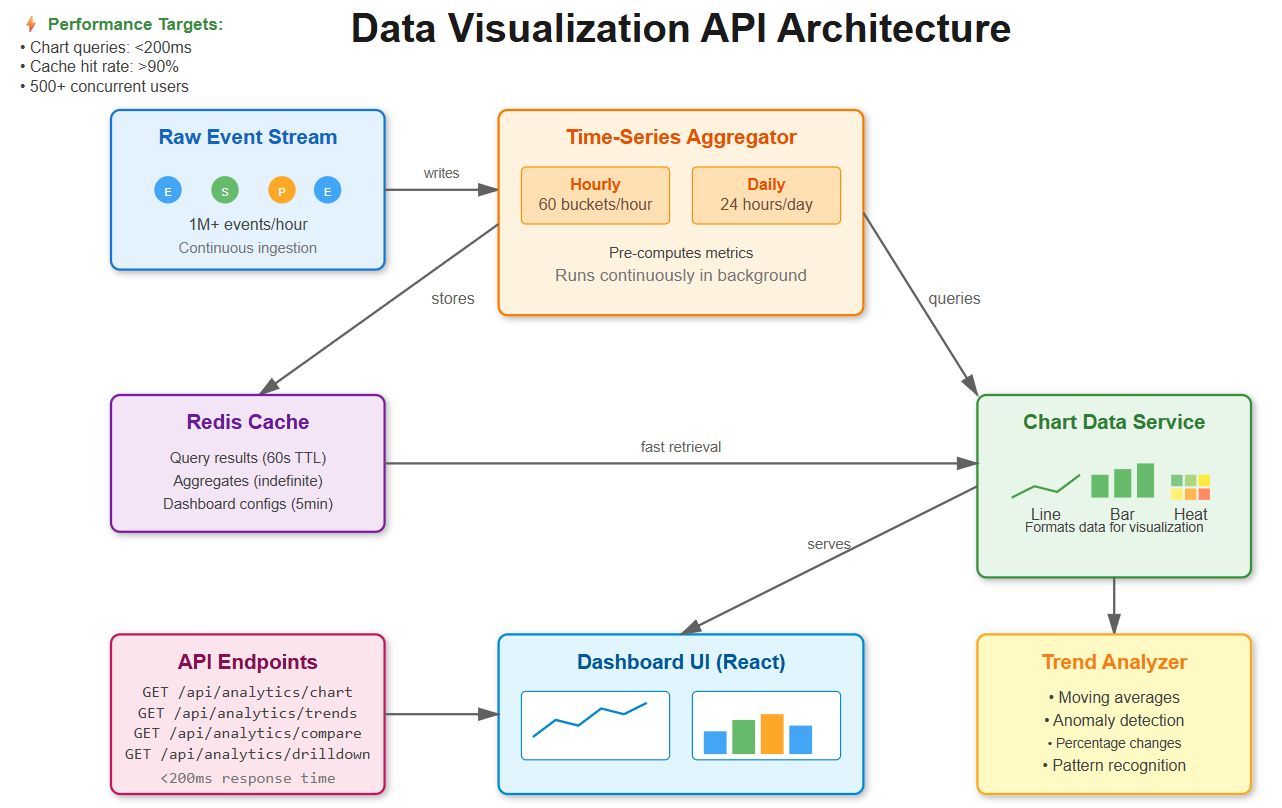
Chart data endpoints that aggregate millions of events into visualization-ready formats
Aggregated data services that pre-compute statistics for instant dashboard loading
Trend analysis API that automatically identifies patterns and anomalies
Comparison tools that benchmark performance across channels and time periods
Drill-down capabilities that let users navigate from high-level summaries to individual events
Think about Grafana’s monitoring dashboards. You can zoom from “server CPU usage across all machines” down to “which specific process caused the spike at 3:47 AM on server-23.” We’re building that same investigative power for notification metrics.
Why This Matters in Real Systems
Let me give you some context about what we’re building:
Netflix processes over 300 million notification events every single day. Their analytics API needs to answer questions like “why did email delivery rates drop 5% yesterday?” in under 200 milliseconds. That’s faster than you can blink.
Slack’s analytics dashboard shows 50+ charts simultaneously. Each chart queries different time ranges and aggregations. Yet somehow, their database doesn’t collapse under the load. How? Through smart pre-aggregation and caching, which we’re building today.
The challenge isn’t just querying data. Anyone can write a SQL query. The real challenge is pre-aggregating metrics efficiently, caching intelligently, and providing drill-down paths that maintain sub-second response times even when users explore billions of events.