

Day 116: Caching Systems
What We’re Building Today
By the end of this session you will have a production-grade caching layer wired into your full-stack infrastructure stack — the same architectural pattern Netflix, Shopify, and GitHub use to absorb traffic spikes without sweating. Here’s the agenda:
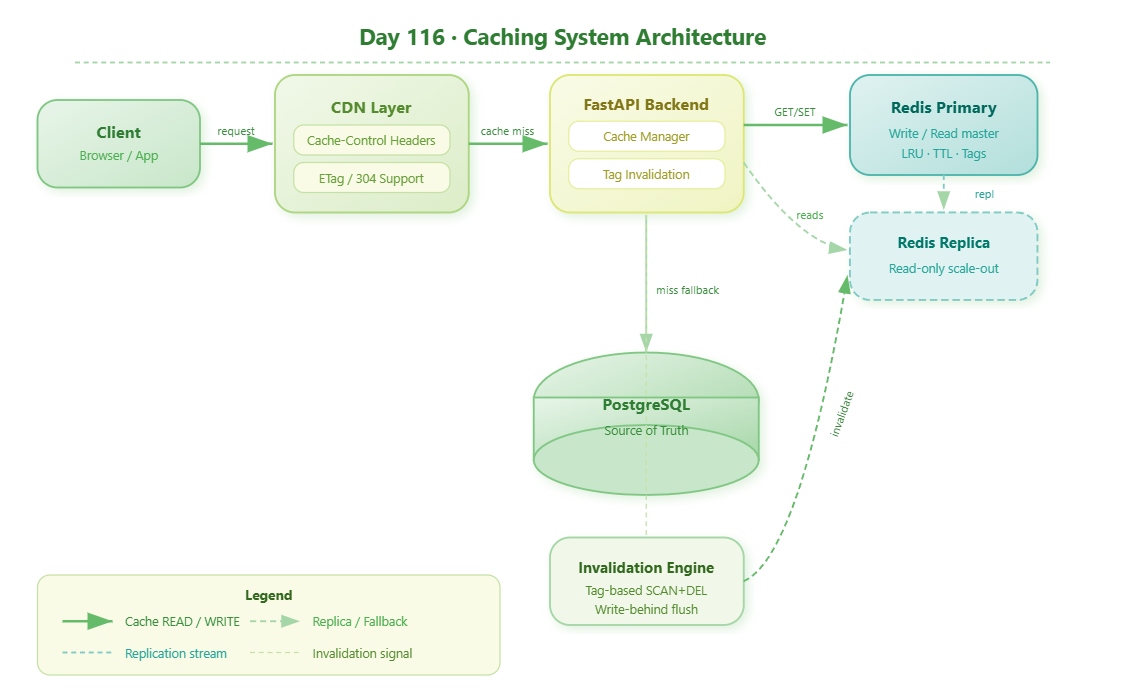
Stand up Redis as a multi-strategy cache (TTL, LRU, write-through, write-behind)
Build a tag-based cache invalidation system that keeps data consistent at scale
Simulate CDN edge caching with cache-control header intelligence
Wire a distributed cache topology — primary + replica coordination
Expose a live metrics dashboard so you can watch cache hit rates climb in real time
Why Caching Is Not Optional
Every millisecond your database spends answering a query it already answered yesterday is money burned and latency earned. Twitter’s timelines, Amazon’s product pages, Stripe’s API — they all lean on caching as the primary shield between end users and expensive data stores.
The subtle insight most engineers miss:
Caching is not about speed alone — it’s about where you spend your consistency budget.
Some data can be stale for 60 seconds. Some can’t be stale for even 1. Your cache strategy is really a contract about acceptable freshness. The hidden trap most engineers fall into is setting one TTL for everything. The right approach is per-resource TTL governed by business requirements.
Core Concepts — The Three Cache Strategies
Before the architecture diagrams, lock in the three patterns you’ll implement. Think of these as three different agreements between your application and your database about who’s responsible for keeping data fresh.
Strategy 1: TTL-Based (Read-Through)
The simplest strategy. Your app asks the cache first. On a miss, it goes to the database, writes the result into cache with a time-to-live expiry, then returns. After TTL seconds the entry disappears automatically.
# Read-Through: cache first, database on miss
value = cache.get(key)
if not value:
value = db.fetch(key) # miss — hit the database
cache.set(key, value, ttl=300) # populate cache for next time
return value
# Risk: stale data between writes. Acceptable for read-heavy data.
Strategy 2: Write-Through
Every write goes to the database first (the authoritative source), then immediately updates the cache. Your cache is never stale after a write because both stores are updated in the same operation.
# Write-Through: database and cache updated together
db.write(value) # authoritative write first
cache.set(key, value) # then sync cache immediately
# Risk: if cache.set() fails after db.write() — data is in DB
# but cache is stale until TTL expires. Consistency risk is low.
Strategy 3: Write-Behind (Write-Back)
The fastest option. Your app writes to cache first, returns immediately to the user, and a background process asynchronously flushes the data to the database on an interval.
# Write-Behind: cache first, async database flush
cache.set(key, value) # cache first — instant response
queue.push(value) # push to background flush queue
# Worker drains queue every 5 seconds → DB
# Risk: if app crashes before flush — data in cache is lost.
# Best for: analytics events, click counters, activity logs.
Important: Never use write-behind for user profile data. If the app crashes between the cache write and the database flush, that profile update is permanently gone. Reserve write-behind for data where a small loss window is acceptable.
Component Architecture
Preparing for a distributed systems interview?
→Download the free Interview Pack
→ Subscribe now to access source code repository - 200 + coding lessons
